
Page 125 - 《中国药房》2025年6期
P. 125
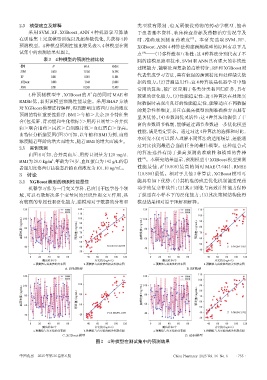
2.3 模型建立及解释 类型没有限制,也无须假设药物的药动学模型,能基
采用 SVM、RF、XGBoost、ANN 4 种机器学习算法 于患者基本资料、临床检查指标及药物治疗情况等及
在训练集上完成模型训练以及超参数优化,共获得4种 时、准确地预测血药浓度 。本研究选取 SVM、RF、
[17]
预测模型。4种模型预测性能比较见表3,4种模型在测 XGBoost、ANN 4 种算法构建预测模型的原因有以下几
试集中的预测结果见图2。 点 ——(1)多样性和互补性:这4种算法分别代表了不
[18]
表3 4种模型的预测性能比较 同的建模思路和技术,SVM 和 ANN 具有强大的非线性
模型 R 2 MAE RMSE 建模能力,能够处理复杂的高维特征;RF和XGBoost则
SVM 0.650 11.384 14.598
RF 0.801 8.010 11.004 代表集成学习方法,具有较强的预测精度和处理缺失数
XGBoost 0.808 7.644 10.808 据的能力。(2)普遍适用性:这4种算法是机器学习中最
ANN 0.701 10.369 13.499
常用的算法,被广泛应用于各类分类和回归任务,具有
2
4 种预测模型中,XGBoost 的 R 高的同时 MAE 和 较强的泛化能力。(3)性能稳定性:这4种算法在处理实
RMSE 低,表明该模型预测性能最佳。采用 SHAP 方法 际数据时表现出良好的性能稳定性,能够适应不同数据
对XGBoost模型进行解释,得到影响度洛西汀血药浓度 的复杂性和维度,并且在提高模型预测准确性方面具有
预测的特征重要性排序:BMI>年龄>其余20个特征集
显著优势。(4)参数调优灵活性:这4种算法均提供了丰
合(包括肝、肾功能和生化指标)>用药日剂量>合并疾
富的参数调节机制,能够通过调节参数进一步优化模型
病>联合用药>民族>白细胞计数>血红蛋白>身高。
性能,满足特定要求。通过对这4种算法的选择和对比,
由特征分析摘要图(图3)可知,以年龄和BMI为例,血药
本研究不仅可以深入理解不同算法的适用场景,还能通
浓度随着年龄的增大而增大,随着BMI的增大而减少。
过对比找到最适合当前任务的最佳模型。这种组合式
2.5 实例预测
的算法选择有助于提高预测的准确性和模型的鲁棒
由图 4 可知,合并高血压、用药日剂量为 120 mg/d、
[19]
BMI为20.0 kg/m 、年龄为74岁、血红蛋白为142 g/L的患 性 。本研究结果显示,预测模型中XGBoost 模型预测
2
2
者服用度洛西汀达稳态后的血药浓度为101.18 ng/mL。 性能最佳,R(0.808)最高的同时 MAE(7.644)、RMSE
3 讨论 (10.808)最低。相对于其他 3 种算法,XGBoost 模型可
3.1 XGBoost模型的预测性能最佳 能具有如下优势:(1)其精准的残差优化机制能适配药
机器学习作为一门交叉学科,已应用于医学各个领 动学的复杂非线性;(2)其正则化与高效计算能力保障
域,可以有效解决多个变量间的共线性和交互作用,具 了模型在小样本下的泛化能力;(3)其决策树结构使得
有较强的专属性和泛化能力,建模时对于数据的分布和 模型结果相对易于理解和解释。
120 120 120 110
110
100
( ng/mL ) ( ng/mL ) 90 ( ng/mL ) 100 ( ng/mL ) 90
100
100
80
80
血药浓度/ 80 预测值/ 70 血药浓度/ 80 预测值/ 70
60
60
50 60 60
50
40 40 Y=0.641X+22.579 Y=0.746X+17.023
40
30 40
0 20 40 60 80 40 60 80 100 120 0 20 40 60
测试样本/个 真实值/(ng/mL) 测试样本/个 真实值/(ng/mL)
a.预测值与真实值的分布图 b.预测值与真实值的相关性散点图 a.预测值与真实值的分布图 b.预测值与真实值的相关性散点图
A. SVM模型 B. RF模型
110
120 120
100
100
( ng/mL ) 100 ( ng/mL ) 80 ( ng/mL ) 100 ( ng/mL ) 90
80
80
80
血药浓度/ 60 预测值/ 60 血药浓度/ 60 预测值/ 70
60
50
Y=0.808X+11.078 40 40 Y=0.746X+13.932
40 40
30
0 20 40 60 80 40 60 80 100 120 0 20 40 60
测试样本/个 真实值/(ng/mL) 测试样本/个 真实值/(ng/mL)
a.预测值与真实值的分布图 b.预测值与真实值的相关性散点图 a.预测值与真实值的分布图 b.预测值与真实值的相关性散点图
C. XGBoost模型 D. ANN模型
图2 4种模型在测试集中的预测结果
中国药房 2025年第36卷第6期 China Pharmacy 2025 Vol. 36 No. 6 · 755 ·