
Page 124 - 《中国药房》2025年6期
P. 124
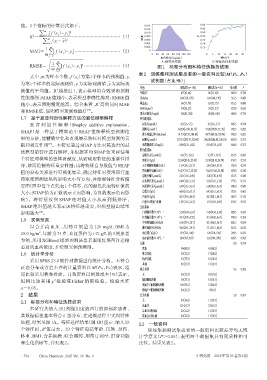
能。3个指标的计算公式如下: 0.014 0.84
0.012 0.82
m
∑ [ f (x )- y ] 2 0.010 0.80
i
i
2
R = i = 1 m - ⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅ (1) 密度 0.008 R 2 0.78
∑ (y - y) 2 0.006 0.76
i
0.004
i = 1
0.74
1 m 0.002 0.72
MAE= ∑ | f (x )- y ⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅ (2) 0
| i
m i 0 20 40 60 80 100 120 140 0 5 10 15 20 25 30
i = 1
血药浓度/(ng/mL) 特征/个
1 m A.标签分布图 B.特征选择折线图
2
RMSE= ∑ [ f (x )- y ] ⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅ (3) 图1 标签分布图和特征选择折线图
m i = 1 i i
表2 训练集和测试集患者的一般资料比较[M(P25,P75 )
式中,m为样本个数, f (x )为第i个样本的预测值,yi 或例数(占比/%%)]
i
-
为第i个样本的实际观测值,y为实际观测值, y为实际观
变量 训练集(n=196) 测试集(n=85) 统计值 P
测值的平均值。R 越接近 1,表示模型拟合效果和预测 年龄/岁 47(30,66) 46(31,62) 869.0 0.734
2
性能越强;MAE值越小,表示模型准确性越高;RMSE值 身高/cm 164(158,170) 164(160,170) 512.5 0.200
2
越小,表示预测精度越高。综合来看,R 高的同时MAE 体重/kg 66(57,78) 63(55,75) 851.5 0.800
2
BMI/(kg/m) 24(20,27) 24(21,27) 637.0 0.635
[14]
和RMSE低,说明模型预测性能好 。
用药日剂量/(mg/d) 80(40,100) 80(40,100) 600.0 0.716
1.7 基于夏普利加性解释方法的最优模型解释 肾功能指标
夏 普 利 加 性 解 释(Shapley additive explanation, 尿素/(mmol/L) 4.2(3.6,5.3) 4.2(3.8,5.3) 845.5 0.938
肌酐/(μmol/L) 69.30(61.98,82.13) 71.80(59.89,77. 20) 742.5 0.282
SHAP)是一种基于博弈论中 SHAP 值解释模型预测结
肾小球滤过率/(mL/min) 91.73(80.73,104.85) 94.75(84.28,105.74) 742.0 0.203
果的方法,能精确量化和直观展示特征对模型预测的贡 尿酸/(μmol/L) 257.15(209.75,320.43) 246.00(206.40,296.10) 869.0 0.735
[15]
献和相互作用 。本研究通过SHAP方法对筛选出的最 血清胱抑素C/(mg/L) 0.88(0.76,1.02) 0.91(0.74,1.03) 844.0 0.757
肝功能指标
优模型的特征进行解释,并根据平均SHAP值来评估每
总胆红素/(μmol/L) 9.6(7.5,12.6) 9.2(7.3,12.9) 833.5 0.865
个特征对模型的整体贡献度,从而确定特征的重要性排 球蛋白/(g/L) 22.60(20.45,25.45) 21.90(20.10,24.70) 834.5 0.553
序,继而绘制特征重要性图;再将特征自身数值与SHAP 天冬氨酸转氨酶/(U/L) 17.9(14.5,21.7) 18.4(14.0,23.9) 755.0 0.239
值的分布关系进行可视化展示,确定特征对度洛西汀血 丙氨酸转氨酶/(U/L) 16.27(11.13,23.24) 17.66(11.60,25.90) 629.0 0.350
总胆汁酸/(μmol/L) 2.83(1.65,4.49) 3.26(1.70,4.59) 833.5 0.549
药浓度预测结果的影响大小与方向,并绘制特征分析摘 直接胆红素/(μmol/L) 2.40(1.82,3.33) 2.50(1.81,3.38) 777.5 0.311
要图(图中每个点代表1个样本,点的颜色代表特征值的 间接胆红素/(μmol/L) 6.99(5.16,9.61) 6.80(4.65,9.65) 906.0 0.947
大小;SHAP值为正数表示正向影响,为负数表示负向影 总蛋白/(g/L) 64.8(61.8,67.1) 64.5(61.5,67.9) 787.5 0.462
白蛋白/(g/L) 42.3(39.6,44.4) 42.5(40.1,44.5) 685.5 0.132
响)。将特征按照 SHAP 绝对值大小从高到低排序,
白蛋白/球蛋白比例 1.87(1.63,2.12) 1.93(1.69,2.09) 834.5 0.553
SHAP 绝对值越大表示该特征越重要,对模型输出结果 生化指标
[16]
9
影响越大 。 白细胞计数/×10 L -1 5.50(4.70,6.67) 5.49(4.54,6.38) 809.5 0.437
红细胞计数/×10 L -1 4.33(4.05,4.72) 4.31(4.08,4.61) 749.0 0.305
12
1.8 实例预测
中性粒细胞百分比/% 53.6(47.4,58.7) 50.3(46.0,56.9) 886.5 0.834
以合并高血压、用药日剂量为 120 mg/d、BMI 为 淋巴细胞百分比/% 34.2(29.1,39.7) 37.1(31.3,42.6) 857.5 0.672
2
20.0 kg/m 、年龄为74岁、血红蛋白为142 g/L的1例患者 血红蛋白/(g/L) 129(121,140) 128(118,138) 749.5 0.223
血小板计数/×10 L -1 224(197,267) 232(199,270) 824.5 0.505
9
为例,采用XGBoost模型预测该患者服用度洛西汀达稳
民族 8.0 0.534
态后的血药浓度,并绘制实例预测图。 汉族 94(48.0) 41(48.2)
1.9 统计学分析 维吾尔族 24(12.2) 17(20.0)
哈萨克族 35(17.9) 16(18.8)
采用SPSS 23.0软件对数据进行统计分析。不符合
其他 43(21.9) 11(12.9)
正态分布或方差不齐的计量资料以 M(P25,P75 )表示,组 联合用药 9.6 0.382
间比较采用秩和检验。计数资料以例数或率(%)表示, 无 26(13.3) 10(11.8)
2
组间比较采用 χ 检验或 Fisher 精确检验。检验水准 辅助睡眠药物 30(15.3) 14(16.5)
奥氮平+辅助睡眠药物 116(59.2) 53(62.4)
α=0.05。 喹硫平+辅助睡眠药物 24(12.2) 8(9.4)
2 结果 合并疾病 5.8 0.761
2.1 标签分布和特征选择结果 无 29(14.8) 11(12.9)
高血压 121(61.7) 52(61.2)
本研究共纳入 281 例服用度洛西汀的抑郁症患者,
高血压+糖尿病 22(11.2) 11(12.9)
其数据标签基本符合正态分布,在建模过程中无须特殊 高血压+冠心病 24(12.2) 11(12.9)
处理,结果见图1A。特征选择结果(图1B)显示,纳入29 2.2 一般资料
2
个特征时,R 值最大。29 个特征包括年龄、民族、身高、 训练集和测试集患者的一般资料比较差异均无统
体重、BMI、合并疾病、联合用药、用药日剂量、肝肾功能 计学意义(P>0.05),表明两个数据集具有同质性和可
和生化指标等,详见表2。 比性。结果见表2。
· 754 · China Pharmacy 2025 Vol. 36 No. 6 中国药房 2025年第36卷第6期