
Page 125 - 《中国药房》2025年11期
P. 125
器学习方法在二分类模型测试集的性能指标超过了训 30
练集的性能,这表明模型在训练过程中已经充分掌握了 25
20
数据的特征和规律,达到了较好的性能。
频率 15
表3 不同分类模型中各机器学习方法的性能指标 10
5
三分类模型 二分类模型 0
0.74 0.75 0.76 0.77 0.78
机器学习方法 准确率(训练 F1分数(训练 AUC 准确率(训练 F1分数(训练 AUC 准确率
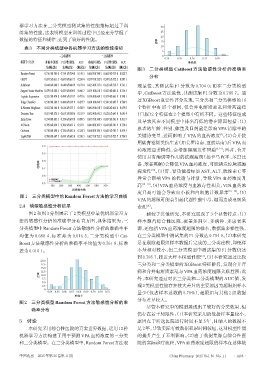
集/测试集) 集/测试集) (测试集) 集/测试集) 集/测试集) (测试集) 图3 二分类模型 CatBoost 方法敏感性分析的准确率
Random Forest 0.716 3/0.705 0 0.714 1/0.704 0 0.519 3 0.668 9/0.740 5 0.668 9/0.739 0 0.822 7
分布
GBDT 0.697 5/0.611 5 0.695 0/0.617 3 0.550 4 0.599 3/0.732 8 0.599 1/0.732 5 0.807 1
AdaBoost 0.644 6/0.640 3 0.640 8/0.644 9 0.677 4 0.625 8/0.717 6 0.625 6/0.718 7 0.761 1 现最佳,其测试集 F1 分数为 0.704 0;而在二分类模型
Support Vector Machine 0.479 1/0.388 5 0.433 9/0.400 3 0.446 2 0.591 0/0.610 7 0.582 4/0.605 8 0.754 5 中,CatBoost 方法最优,其测试集 F1 分数为 0.785 7。通
Logistic Regression 0.525 3/0.474 8 0.494 5/0.510 7 0.471 6 0.596 0/0.664 1 0.593 4/0.665 9 0.748 1
过XGBoost重要性评分发现,三分类和二分类模型的16
Ridge Classifier 0.530 9/0.388 5 0.480 0/0.391 9 0.427 7 0.601 0/0.694 7 0.598 3/0.695 7 0.766 9
K-Nearest Neighbors 0.652 3/0.546 8 0.634 2/0.571 3 0.478 9 0.648 9/0.610 7 0.648 2/0.612 6 0.679 0 个特征中有 15 个相同,仅合并电解质紊乱和给药途径
Decision Tree 0.653 4/0.575 5 0.653 3/0.580 6 0.513 9 0.632 4/0.641 2 0.632 1/0.643 0 0.641 4 (口服)2个特征在2个模型中有所不同。这些特征组成
Extra Trees 0.734 0/0.683 5 0.729 6/0.678 0 0.499 5 0.693 7/0.740 5 0.693 5/0.741 0 0.811 9 及导致其在不同模型中排名高低的潜在原因包括:(1)
XGBoost 0.709 6/0.654 7 0.706 9/0.651 2 0.537 1 0.644 0/0.702 3 0.643 8/0.701 9 0.778 6
CatBoost 0.730 6/0.690 6 0.726 6/0.683 6 0.524 3 0.668 8/0.786 3 0.668 5/0.785 7 0.819 5 患者的年龄、性别、体重及日剂量是影响 VPA 清除率的
[7]
LightGBM 0.700 8/0.647 5 0.699 3/0.645 0 0.550 5 0.627 5/0.725 2 0.627 1/0.725 7 0.784 8 关键协变量,进而影响了 VPA 的血药浓度 。(2)合并使
用碳青霉烯类抗生素(如美罗培南、亚胺培南)后VPA血
1.0
药浓度显著降低,会增加癫痫发作风险 [5,14] ;再者,合并
0.9
使用具有酶诱导作用的抗癫痫药(如卡马西平、苯巴比
准确率 0.8 妥、苯妥英钠)会降低VPA血药浓度,可能诱发惊厥或癫
0.7
[15]
痫发作 。(3)肝、肾功能指标如 AST、ALT、胱抑素 C 等
0.6
训练准确率 异常会影响 VPA 的代谢与排泄,导致 VPA 血药浓度升
交叉验证准确率
0.5 [16―18]
100 200 300 400 500 600 700 高 。(4)VPA血药浓度与血液毒性相关,VPA血药浓
训练样本数 [19―20]
度升高可能会导致血小板和白细胞计数异常 。(5)
图1 三分类模型中的Random Forest方法的学习曲线
VPA的超限可能会引起代谢性酸中毒,继而造成电解质
2.4 模型敏感性分析结果 紊乱 。
[21]
图 2 和图 3 分别展示了 2 类模型中最优机器学习方 相较于其他研究,本研究展现了 3 个显著特点:(1)
法的敏感性分析的准确率分布直方图,具体结果为:三 样本源自综合性医院,覆盖多科室、多病种、多患者来
分类模型中Random Forest方法敏感性分析的准确率平 源,还包括VPA血药浓度超限的样本,数据集多样性强,
均值为 0.680 4、标准差为 0.016 5,二分类模型中 Cat‐ 在三分类模型中测试集的F1分数达0.704 0。(2)本研究
Boost 方法敏感性分析的准确率平均值为 0.761 8、标准 是在剔除超限组样本数据后完成的二分类建模,即便样
差为0.010 1。 本量相对较小,但二分类模型中测试集的 F1 分数仍达
[13]
到0.785 7,接近大样本模型性能 。(3)本研究通过比较
20.0
17.5 三分类和二分类模型的XGBoost特征排名,发现合并肾
15.0
12.5 病和合并电解质紊乱与VPA血药浓度超限关联性强;此
频率 10.0
7.5 外,本研究通过对比三分类和二分类模型的AUC值,发
5.0
2.5 现2类模型性能存在较大差异的主要原因为超限组样本
0
0.64 0.65 0.66 0.67 0.68 0.69 0.70 0.70 0.72 量少(仅占样本总数的 5.76%),超限组与其他 2 组数据
准确率
分布差异较大。
图2 三分类模型Random Forest方法敏感性分析的准
尽管本研究中的模型展现出了较好的分类效果,但
确率分布
仍存在若干局限性:(1)本研究采用的数据样本量较小,
3 讨论 原因在于所选医院运行时间不足5年,且纳入的数据不
本研究采用综合性医院的真实世界数据,运用12种 足2年,导致实际有效数据积累时间较短,这对模型性能
机器学习方法构建了用于预测 VPA 血药浓度的三分类 的提升产生了不利影响。(2)由于数据集源自综合性医
和二分类模型。在三分类模型中,Random Forest方法表 院的实际诊疗流程,VPA血药浓度超限的样本在总体数
中国药房 2025年第36卷第11期 China Pharmacy 2025 Vol. 36 No. 11 · 1403 ·