
Page 96 - 《中国药房》2026年2期
P. 96
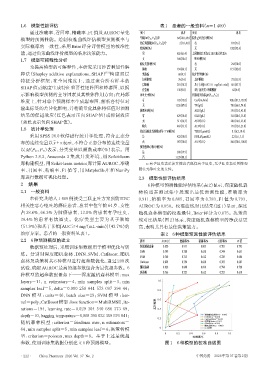
1.6 模型性能评估 表1 患者的一般资料(n=1 409)
通过准确率、召回率、精确率、F1值及AUROC量化 项目 患者 项目 患者
模型的预测性能。绘制校准曲线评估模型预测概率与 年龄[M(P 25,P 75)]/岁 64(58.0,69.0)院外止吐治疗/例(%)
化疗周期数[M(P 25,P 75)]/个 2(1.0,4.0) 有 107(7.6)
实际概率的一致性,采用 Brier 评分评估模型的校准性 性别/例(%) 无 1 302(92.4)
能,通过决策曲线评价模型的临床决策能力。 男 865(61.4) 上周期化疗后发生HEC相关性恶心
1.7 模型可解释性分析 女 544(38.6) 呕吐/例(%)
癌症类别/例(%) 有 254(18.0)
为提高模型的可解释性,本研究采用沙普利加性解
肺癌 934(66.3) 无 1 155(82.0)
[12]
释法(Shapley additive explanations,SHAP) 构建双层 乳腺癌 60(4.3) 化疗类型/例(%)
特征分析框架:在全局维度上,通过聚合所有样本的 妇科肿瘤 76(5.4) 基于顺铂 731(51.9)
胃肠癌 201(14.2) 基于卡铂[AUC≥4 mg/(mL·min)] 616(43.7)
SHAP 值贡献度生成特征重要性矩阵图和蜂群图,以揭
食管癌 138(9.8) 基于蒽环类+环磷酰胺 62(4.4)
示影响模型预测的主导因素及其整体作用方向;在局部 孕吐史 /例(%) 代谢相关指标[M(P 25,P 75)]
a
维度上,针对单个预测样本生成瀑布图,解析各特征对 有 183(13.0) Ccr/(mL/min) 100.6(81.5,129.9)
无 1 226(87.0) TP/(g/L) 70.0(66.0,74.0)
输出标签的差异化影响,并精确量化具体特征值对预测
饮酒史/例(%) ALB/(g/L) 39.0(35.0,42.0)
结果的促进效应(红色表示正向 SHAP 值)或抑制效应 有 429(30.4) GLB/(g/L) 31.0(28.0,35.0)
(蓝色表示负向SHAP值)。 无 511(36.3) AST/(U/L) 20.0(16.0,25.0)
缺失 469(33.3) ALT/(U/L) 17.0(12.0,25.0)
1.8 统计学处理
化疗前夜患者睡眠时间<7 h/例(%) TBILI/(μmol/L) 8.1(6.2,10.4)
采用 SPSS 26.0 软件进行统计学处理,符合正态分 是 422(30.0) DBILI/(μmol/L) 2.2(1.6,3.1)
布的连续变量以x±s表示,不符合正态分布的连续变量 否 987(70.0) ALP/(U/L) 86.0(70.0,108.5)
预期性恶心呕吐/例(%)
以 M(P25,P75 )表示,分类变量以频数或率(%)表示。用
是 280(19.9)
Python 3.8.3、Anaconda 3 集成开发环境,用 Scikit-learn 否 1 129(80.1)
库构建模型,用Scikit-learn metrics库计算AUROC、准确 a:有孕吐史表示该女性患者既往有孕吐史,无孕吐史表示男性和
率、召回率、精确率、F1 值等,用 Matplotlib 库和 NumPy 既往无孕吐史的女性。
库进行数据可视化处理。 2.3 模型性能评估结果
2 结果 6种模型预测性能评估结果(表2)显示,深度随机森
2.1 一般资料 林模型在测试集中展现出最优预测性能,准确率为
本研究共纳入1 409例接受三联止吐方案预防HEC 0.911,精确率为 0.805,召回率为 0.783,F1 值为 0.793,
相关性恶心呕吐的癌症患者,患者中位年龄64岁,女性 AUROC 为 0.850。校准曲线对比结果(图 1)显示,深度
占 38.6%,66.3% 为肺癌患者,13.0% 的患者有孕吐史, 随机森林模型的校准最佳,Brier 评分为 0.075。决策曲
30.4% 的患者有饮酒史。化疗类型主要为基于顺铂 线对比结果(图 2)显示,深度随机森林模型的净获益更
(51.9%)和基于卡铂[AUC≥4 mg/(mL·min)](43.7%)的 高,表明其具有最佳决策能力。
治疗方案。患者的一般资料见表1。 表2 6种模型预测性能评估结果
2.2 6种预测模型的建立 模型 AUROC 准确率/% 精确率/% 召回率/% F1值
数据预处理后,采用训练集数据用于模型优化与训 深度随机森林 0.850 0.911 0.805 0.783 0.793
DNN 0.799 0.780 0.638 0.744 0.655
练。分别对深度随机森林、DNN、SVM、CatBoost、随机
SVM 0.760 0.713 0.612 0.729 0.606
森林及决策树共 6 种模型进行超参数优化,通过 200 次 CatBoost 0.829 0.794 0.660 0.787 0.681
试验,确定AUROC最高的超参数组合为最优超参数。6 随机森林 0.828 0.848 0.698 0.794 0.728
决策树 0.766 0.723 0.612 0.723 0.610
种模型的超参数配置如下——深度随机森林模型:max
layers=11,n estimators=4,min samples split=3,min 1.0
samples leaf=5,delta=0.000 250 841 573 097 396 44; 0.8
DNN 模 型 :units=46,batch size=29;SVM 模 型 :ker‐
nel=poly;CatBoost模型:loss function=MultiRMSE,ite- 实际概率 0.6
rations=194,learning rate=0.029 304 540 686 373 69, 0.4
depth=10,bagging temperature=0.008 390 032 359 576 841; 深度随机森林(Brier=0.075)
DNN(Brier=0.518)
0.2 CatBoost(Brier=0.119)
随机森林模型:criterion=friedman mse,n estimators= 决策树(Brier=0.161)
SVM(Brier=0.716)
随机森林(Brier=0.093)
64,min samples split=5,min samples leaf=4;决策树模 0 完美校准
0 0.2 0.4 0.6 0.8 1.0
型:criterion=poisson,max depth=8。基于上述最优超 预测概率
参数,使用训练集数据分别建立6种预测模型。 图1 6种模型的校准曲线图
· 222 · China Pharmacy 2026 Vol. 37 No. 2 中国药房 2026年第37卷第2期