
Page 109 - 《中国药房》2025年19期
P. 109
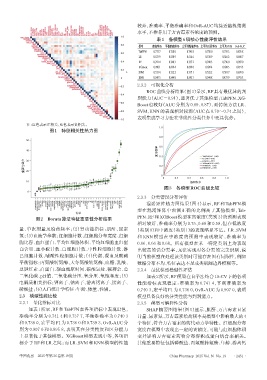
较差,准确率、平衡准确率和OvR-AUC均接近随机猜测
水平,不推荐用于万古霉素谷浓度的预测。
表1 各模型6项核心性能评估结果
模型 准确率/% 平衡准确率/% 宏平均精确率/% 宏平均召回率/% 宏平均F1/% OvR-AUC
TabPFN 0.737 7 0.738 0 0.745 8 0.738 0 0.739 3 0.895 8
LR 0.533 9 0.530 9 0.516 6 0.530 9 0.516 2 0.698 7
RF 0.741 4 0.740 3 0.737 2 0.740 3 0.736 0 0.907 0
XGBoost 0.700 1 0.699 4 0.699 0 0.699 4 0.698 5 0.871 3
r SVM 0.535 4 0.532 2 0.517 1 0.532 2 0.510 7 0.699 0
KNN 0.549 3 0.544 8 0.545 3 0.544 8 0.473 9 0.741 3
2.3.2 可视化分析
ROC曲线分析结果(图3)显示,RF具有最优异的判
别能力(AUC=0.91),显著优于其他模型;TabPFN、XG‐
Boost 也较好(AUC 分别为 0.89、0.87),而传统方法 LR、
SVM、KNN的表现相对较弱(AUC在0.70~0.74之间),
表明集成学习方法在非线性分类任务中更具优势。
注:红色表示正相关,蓝色表示负相关。
1.0
图1 特征相关性热力图
0.8
50
真阳性率
40 0.6
0.4
TabPFN(AUC=0.89)
LR(AUC=0.70)
30
重要性得分 20 0.2 XGBoost(AUC=0.87)
RF(AUC=0.91)
SVM(AUC=0.70)
KNN(AUC=0.74)
0
0 0.2 0.4 0.6 0.8 1.0
10 假阳性率
图3 各模型ROC曲线比较
0
2.3.3 分类错误分布评估
混淆矩阵热力图结果(图 4)显示,RF 和 TabPFN 模
型在混淆矩阵中预测正确的比例高于其他模型,Tab‐
特征
图2 Boruta算法特征重要性分析结果 PFN、RF 和 XGBoost 模型在高浓度(类别 2)的预测表现
相对较好,准确率分别为 0.75、0.60 和 0.59,但在低浓度
量、单次剂量及给药频率;(2)肾功能指标:肌酐、尿素 (类别 0)和中浓度(类别 1)的表现略显不足。LR、SVM
氮;(3)血液学参数:红细胞计数、红细胞分布宽度、红细 和 KNN 模型在中浓度的预测中表现较好,准确率为
胞比容、血红蛋白、平均红细胞体积、平均红细胞血红蛋 0.66、0.66 和 0.68。所有模型在某一特定类别上均表现
白含量、血小板计数、白细胞计数、中性粒细胞计数、淋 出较高的误分类率,无法实现对各分类的完美识别,说
巴细胞计数、嗜酸性粒细胞计数;(4)代谢、凝血及酸碱 明当前模型在处理该类别时可能存在固有局限性,例如
平衡指标:丙氨酸转氨酶、天冬氨酸转氨酶、血糖、乳酸、 数据分布不均、特征表达不足或类别间边界模糊等。
总胆红素、白蛋白、凝血酶原时间、碳酸氢盐、碱剩余、总 2.3.4 最优模型稳健性评估
二氧化碳、pH值、二氧化碳分压、氧分压、氧饱和度;(5) 如表2所示,RF模型在自举法结合10-CV下的各项
电解质相关指标:钾离子、钠离子、游离钙离子、镁离子、 性能指标表现稳定:准确率为 0.741 4,平衡准确率为
磷酸盐;(6)人口统计学特征:年龄、体重、性别。 0.740 3,宏平均F1为0.736 0,OvR-AUC为0.907 0,表明
2.3 模型性能比较 模型具备良好的分类性能与判别能力。
2.3.1 量化指标对比 2.3.5 模型可解释性分析
如表1所示,RF和TabPFN在各项指标中表现出色, SHAP 摘要图结果(图5)显示,肌酐、万古霉素日累
准确率分别为 0.741 4 和 0.737 7,平衡准确率为 0.740 3 计量、尿素氮、万古霉素给药频率是模型中影响最大的4
和 0.738 0,宏平均 F1 为 0.736 0 和 0.739 3,OvR-AUC 分 个特征,符合万古霉素的药代动力学特性。红细胞分布
别为 0.907 0 和 0.895 8,表明其在分类精度和区分能力 宽度在模型中表现出一定的贡献度,可能与红细胞体积
上显著优于其他模型。XGBoost模型表现中等,各项指 变异影响万古霉素药物分布容积或蛋白结合率相关。
标介于 RF 和 LR 之间;而 LR、SVM 和 KNN 模型的性能 其他重要特征包括磷酸盐、丙氨酸转氨酶、年龄、游离钙
中国药房 2025年第36卷第19期 China Pharmacy 2025 Vol. 36 No. 19 · 2451 ·