
Page 64 - 2020年20期
P. 64
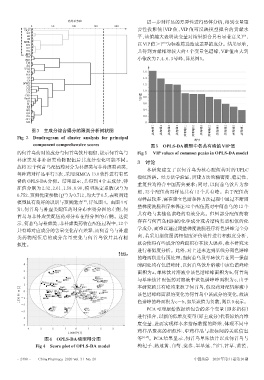
离差平方和 进一步对样品的差异性进行整体分析,得到变量重
0 50 100 150 200
GQZ 要性投影值(VIP 值,VIP 值可反映模型拟合的贡献水
SD
[5]
BS 平,该值越大表明该变量对结果拟合具有显著意义) ,
DS
MHL [16]
DG 以VIP值>1 为标准筛选造成差异的成分。结果显示,
GC
HQ 共得到贡献相对较大的 4 个变量色谱峰,VIP 值由大到
MD
HH
JMZ 小依次为7、4、6、3号峰,详见图5。
TM
SQ
YYH
XS 1.6
NX
CS 1.4
CP
WWX 1.2
CX
DZ 1.0
ZX
CBZ
DanS VIP值 0.8
SZ
FL 0.6
RS
GG 0.4
QH
DH 0.2
JXT
SJS 0
图3 主成分综合得分的聚类分析树状图 共有峰7 共有峰4 共有峰6 共有峰3 共有峰11 共有峰10 共有峰9 共有峰12 共有峰8 共有峰2 共有峰5 共有峰1
Fig 3 Dendrogram of cluster analysis for principal
峰号
component comprehensive scores 图5 OPLS-DA模型中各共有峰的VIP值
的何首乌药对的成分与何首乌饮片相似,提示何首乌与 Fig 5 VIP values of common peaks in OPLS-DA model
补虚类及非补虚类药物配伍后其成分变化可能不同。
3 讨论
故将32个何首乌配伍药对分为补虚类与非补虚类两类,
本研究建立了以何首乌为核心配伍药对的 UPLC
每种药对样品平行3次,采用SIMCA 13.0软件进行有监
指纹图谱。经方法学验证,所建方法的精密度、稳定性、
督的 OPLS-DA 分析。结果显示,共得到 4 个主成分,特
重复性均符合中国药典要求;同时,以何首乌饮片为参
2
征值分别为 2.32、2.61、1.58、0.90,模型决定系数(R )为
照,32 个配伍药对样品共有 12 个共有峰。由于配伍药
0.752、预测优度参数(Q )为0.712,均大于0.5,表明所建
2
对样品较多,需在建立色谱条件方法过程中通过不断调
模型具有良好的识别与预测能力 ,详见图4。由图4可
[16]
整梯度洗脱程序来保证32个配伍药对中何首乌的12个
知,何首乌与补虚类配伍药对分布在得分图的左侧,何
共有峰与其他色谱峰的有效分离。但因部分配伍药物
首乌与非补虚类配伍药对分布在得分图的右侧。这提
存在与何首乌相同的化学成分或者结构类型相似的化
示,何首乌与补虚类、非补虚类药物在配伍过程中,12个
学成分,而难以通过调整梯度洗脱程序将色谱峰完全分
共有峰对应成分的含量变化存在差异,而何首乌与补虚
类药物配伍后的成分含量变化与何首乌饮片具有相 离,若采用指纹图谱相似度评价软件进行相似度分析,
似性。 就会使得有些成分的峰面积存在较大误差,故本研究未
进行相似度分析。此外,对上述未达到基线分离色谱峰
补虚类
非补虚类
的峰面积进行预处理:当何首乌及单味饮片在同一保留
4 时间处均有色谱峰时,以何首乌饮片溶液中该色谱峰峰
3 面积为 a,单味饮片溶液中该色谱峰峰面积为 b,何首乌
2
与单味饮片配伍药对溶液中该色谱峰峰面积为 c,由于
1
to [1] 0 本研究的共有峰均来源于何首乌,假设药对配伍溶液中
该色谱峰峰面积的变化为何首乌中该成分的变化,故该
1.336 96 -1 色谱峰的峰面积为c-b,如果该值为负数,则以0表示。
-2
PCA 可对原始数据所包含的多个变量(即多指标)
-3
进行拟合,以新的低维度变量(即主成分)代替原始高维
-4
度变量,进而实现样本多指标数据的降维,体现不同中
-5
-4 -3 -2 -1 0 1 2 3
1.00067*[1] 药样品聚类的相似性、中药样品与指标间的关联信息
图4 OPLS-DA模型得分图 等 [4,17] 。PCA 结果显示,何首乌单味饮片以及何首乌与
Fig 4 Score plot of OPLS-DA model 枸杞子、熟地黄、白芍、党参、墨旱莲、当归、甘草、黄芪、
·2490 · China Pharmacy 2020 Vol. 31 No. 20 中国药房 2020年第31卷第20期