
Page 9 - 《中国药房》2020年22期
P. 9
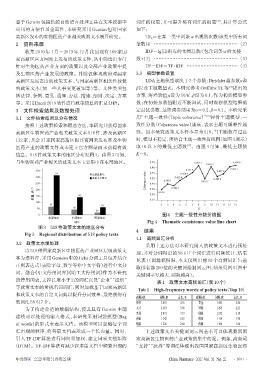
鉴于Gensim包提供的自然语言处理工具在文本挖掘中 词汇的权重,并可提升稀有词汇的权重 ,其计算公式
[15]
应用的方便性及全面性,本研究采用 Gensim 包对国家 如下:
高新区发布的生物医药产业相关政策文本展开研究。 TFw=在某一类中词条w出现的次数/该类中所有词
2 资料来源 条数目 … … … … … … … … … … … … … … … … … … (2)
收集 2010 年 1 月-2019 年 12 月我国现有 169 家国 IDF=Ig[语料库的文档总数/(包含词条w的文楼
家高新区官方网站上发布的政策文件,从中筛选出专门 数+1)] … … … … … … … … … … … … … … … … … … (3)
针对生物医药产业方面的政策以及全部产业政策中提 TF-IDF=TF·IDF … … … … … … … … … … … (4)
及生物医药产业发展的政策。排除仅体现政府对国家 3.3 模型参数设置
高新区发展态度的政策文本、与国家高新区相关性较低 LDA主题模型取决于3个参数:Dirichlet超参数α和
[13]
的政策文本(如一些人事变更通知等)等。文件类型包 β以及主题数量 K。本研究参考 Griffiths TL 等 提出的
括法律、条例、意见、通知、办法、措施、细则、决定、方案 方案,将经验值α设为 50/K、β设为 0.1,作为初始模型参
等。采用Excel 2019软件进行政策信息的汇总分析。 数;在初始参数值附近不断调试,同时观察模型结果确
3 文件检索结果及数据处理 定最优参数,最终调参结果为α=0.2、β=0.1。本研究采
[16]
3.1 文件检索结果及分布情况 用“主题一致性(Topic coherence)” 评价主题模型,一
按照上述政策检索和筛选方法,本研究共获得国家 致性分数(Coherence value)越高,表示主题可解释性越
高新区生物医药产业相关政策文本 518 件,涉及高新区 强。因本研究政策文本样本量为 518,当主题数量过高
132家,其余37家国家高新区因其官网未发布涉及生物 时,模型不稳定,须结合主题一致性折线图(如图4所示)
[17]
医药产业的政策文件或未建立官方网站而未获得有效 取 10 以下的最优主题数 。由图 4 可知,最优主题数
信息。518件政策文本的地区分布见图3。由图3可知, K=8。
与生物医药产业相关的政策文本主要集中在东部地区。 0.48 0.467 7 0.468 6
0.463 4
0.46
350 0.441 7 0.437 2 0.463 1
314 高新区数量 0.44 0.426 9
300 政策文本数量 0.42 0.412 4 0.427 0
250 Coherence value 0.40 0.399 1 0.419 1
家/个 200 0.38 0.378 1 0.399 3
数量, 150 142 0.36
100 0.34
67 62 2 3 4 5 6 7 8 9 10 11 12 13 14
50 45 K
20
0 图4 主题一致性分数折线图
东部地区 中部地区 西部地区
地区 Fig 4 Thematic consistence value line chart
图3 518件政策文本的地区分布
4 结果
Fig 3 Regional distribution of 518 policy texts
4.1 高频词汇分析
3.2 政策文本预处理
采用上述方法对本研究纳入的政策文本进行预处
以518件国家高新区生物医药产业园区层级政策文
理,并对分词得出的 58 617 个词汇进行词频统计,结果
本为语料库,采用Genisim中的Jieba分词工具包并结合
见表 1(因篇幅所限,本文仅列出前 10 个高频词汇);选
正则表达式(去除字母、数字等非中文字符)进行中文分
取排名前200位的关键词绘制词云图,结果见图5(图中
词。融合《中文停用词库》《哈工大停用词》作为本研究
关键词字号越大,词频越高)。
的停用词表,去掉长度小于2的词汇以及“企业”“组织”
表1 政策文本高频词汇(前10个)
等政策文本的常规名词词汇,同时加载基于国家高新区
Tab 1 High-frequency words of policy texts(Top 10)
和政策文本的自定义词典以提升分词效果,最终获得有
高频词汇 词频,次 占比,% 高频词汇 词频,次 占比,%
效词汇58 617个。 项目 2 441 4.16 资金 1 443 2.46
为了构建合适的数据结构,使其具有 Gensim 主题 人才 2 319 3.96 补助 1 295 2.21
支持 2 071 3.53 创业 1 232 2.10
建模可以处理的输入格式,本研究采用词袋模型(Bag 补贴 1 542 2.63 科技 1 114 1.90
of words)的形式来表示文档。该模型可以忽略每个词 创新 1 526 2.60 机构 1 104 1.88
汇出现的顺序,将每篇文档表示成一个长向量。同时, 上述政策文本关键词词云图基本可以体现我国国
引入 TF-IDF 算法进行词向量加权,建立词项文档矩阵 家高新区生物医药产业政策的集中情况。例如,高频词
(DTM)。TF-IDF算法可减少在多篇文档中频繁出现的 “支持”“扶持”等词汇体现出我国国家高新区生物医药
中国药房 2020年第31卷第22期 China Pharmacy 2020 Vol. 31 No. 22 ·2691 ·